
How browsers work?
标准浏览器的幕后
介绍
- 所谓的浏览器
主流浏览器:IE,FF,Safari,Chrome,Opera
部分开源的有FF,Chrome,Safari,W3C统计这三大浏览器占领市场的6成份额。
- 浏览器主要功能特性
The browser main functionality is to present the web resource you choose, by requesting it from the server and displaying it on the browser window.
- 浏览器的主要功能是呈现你所选择的资源,通过向服务端请求并展示在浏览器窗口。
- 浏览器用户交互有很多类似之处,其中便是:
Address bar for inserting the URI---url地址栏
Back and forward buttons---前进后退按钮
Bookmarking options---书签选择
A refresh and stop buttons for refreshing and stopping the loading of current documents---刷新和停止刷新和阻止加载当前文档
Home button that gets you to your home page---主页
Strangely enough, the browser’s user interface is not specified in any formal specification, it is just good practices shaped over years of experience and by browsers imitating each other(浏览器用户界面并非以任何标准区分而区分,而是多年的应用习惯塑造了了其不谋而合的特性). The HTML5 specification doesn’t define UI elements a browser must have, but lists some common elements. Among those are the address bar, status bar and tool bar. There are, of course, features unique to a specific browser like Firefox downloads manager. More on that in the user interface chapter.
- 浏览器高水平结构
主要组件如下
1.The user interface (UI界面)- this includes the address bar, back/forward button, bookmarking menu etc. Every part of the browser display except the main window where you see the requested page.
2.The browser engine(引擎) - the interface for querying and manipulating the rendering engine.
3. The rendering engine(渲染引擎) - responsible for displaying the requested content. For example if the requested content is HTML, it is responsible for parsing the HTML and CSS and displaying the parsed content on the screen.
4. Networking(网络) - used for network calls, like HTTP requests. It has platform independent interface and underneath implementations for each platform.
5. UI backend(UI后端) - used for drawing basic widgets like combo boxes and windows. It exposes a generic interface that is not platform specific. Underneath it uses the operating system user interface methods.
6. JavaScript interpreter(JS解释器). Used to parse and execute the JavaScript code.
7.Data storage(数据存储). This is a persistence layer. The browser needs to save all sorts of data on the hard disk, for examples, cookies. The new HTML specification (HTML5) defines 'web database' which is a complete (although light) database in the browser.
*请注意,Chrome与大多数浏览器不同,它拥有多个呈现引擎实例,每个标签一个。 每个选项卡是一个单独的过程。
组件通信
FF和Chrome都有专门的通信结构,下边讨论。
渲染引擎
The responsibility of the rendering engine is well… Rendering, that is display of the requested contents on the browser screen.
- 渲染即在浏览器上显示请求的内容 By default the rendering engine can display HTML and XML documents and images. It can display other types through a plug-in (a browser extension). An example is displaying PDF using a PDF viewer plug-in. We will talk about plug-ins and extensions in a special chapter. In this chapter we will focus on the main use case - displaying HTML and images that are formatted using CSS.
- 渲染引擎—Rendering engines
Our reference browsers - Firefox, Chrome and Safari are built upon two rendering engines. Firefox uses Gecko - a “home made” Mozilla rendering engine. Both Safari and Chrome use Webkit.
FF,Chrome,Safari 建立在两个引擎之上。FF运用Gecko内核—一个家装的Mozilla渲染引擎。Safari和Chorme用的是Webkit内核。 Webkit is an open source rendering engine which started as an engine for the Linux platform and was modified by Apple to support Mac and Windows. See http://webkit.org/ for more details.
Webkit是一个开源渲染引擎,起初在linux平台作引擎并被Apple改造应用到Mac和window系统。
- 主流(main flow)
The rendering engine will start getting the contents of the requested document from the networking layer. This will usually be done in 8K chunks.
- 渲染引擎从网络层获取文档内容,这通常在8k快完成。
- 渲染引擎将以解析html文档和转换标签到所谓的文档树—DOM节点上开始。它将解析样式数据,包含内敛样式和外联样式。这些样式信息以及可视化的指令将用于创建另一个树–渲染树。
- 渲染树包含具有视觉属性(visual attributes如颜色和尺寸)的矩形。 矩形以正确的顺序显示在屏幕上。 在渲染树的构造之后,它经过“布局(layout)”过程。 这意味着给每个节点在其应该出现在屏幕上的确切坐标。 下一个阶段是绘画(pianting) - 渲染树将被遍历,每个节点将使用UI后端图层绘制。 重要的是要了解这是一个渐进(gtadual process)的过程。 为了获得更好的用户体验,渲染引擎将尽快尝试在屏幕上显示内容。 它不会等到所有的HTML被解析之后才开始构建和布局渲染树。 内容的一部分将被解析和显示,同时该过程继续保持来自网络的其余内容。
- 主流示例, 解析和DOM树结构
Although Webkit and Gecko use slightly different terminology, the flow is basically the same. a.一般解析
- 语法
Since parsing is a very significant(重要,有意义) process within the rendering engine, we will go into it a little more deeply. Let’s begin with a little introduction about parsing. Parsing a document means translating it to some structure that makes sense(转换成有意义的结构) - something the code can understand and use. The result of parsing is usually a tree of nodes that represent the structure of the document(解析的结果通常是表示文档结构的节点树). It is called a parse tree or a syntax tree(解析树||语法树).
Parsing is based on the syntax rules the document obeys - the language or format it was written in. Every format you can parse must have deterministic(确定性) grammar consisting of vocabulary and syntax rules. It is called a context free grammar. Human languages are not such languages and therefore cannot be parsed with conventional parsing techniques.
Parser +Lexer combination组合
arsing can be separated into two sub processes - lexical analysis and syntax analysis.
Lexical analysis is the process of breaking the input into tokens(词法分析是将输入分解成符记的过程). Tokens are the language vocabulary - the collection of valid building blocks. In human language it will consist of all the words that appear in the dictionary for that language. Syntax analysis is the applying of the language syntax rules(语法分析就是语言语法规则的运用). Parsers usually divide the work between two components - the lexer(sometimes called tokenizer) that is responsible for breaking the input into valid tokens, and the parser that is responsible for constructing the parse tree by analyzing the document structure according to the language syntax rules. The lexer knows how to strip irrelevant characters like white spaces and line breaks.
The parsing process is iterative. The parser will usually ask the lexer for a new token and try to match the token with one of the syntax rules. If a rule is matched, a node corresponding to the token will be added to the parse tree and the parser will ask for another token. If no rule matches, the parser will store the token internally, and keep asking for tokens until a rule matching all the internally stored tokens is found. If no rule is found then the parser will raise an exception. This means the document was not valid and contained syntax errors.
Translation改变
Many times the parse tree is not the final product. Parsing is often used in translation - transforming the input document to another format. An example is compilation. The compiler that compiles a source code into machine code first parses it into a parse tree and then translates the tree into a machine code document.
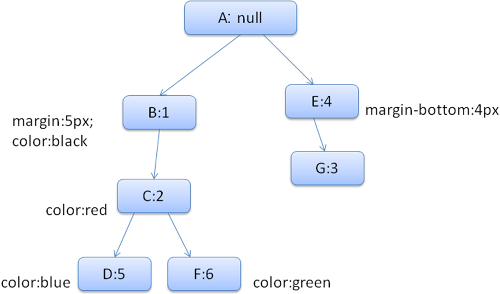
解析示例
- Formal definitions for vocabulary and syntax词法标准定义 Vocabulary is usually expressed by regular expressions. We said that a language can be parsed by regular parsers if its grammar is a context frees grammar. An intuitive definition of a context free grammar is a grammar that can be entirely expressed in BNF. For a formal definition see http://en.wikipedia.org/wiki/Context-free_grammar
- Types of parsers解析器类型 There are two basic types of parsers - top down parsers(自上而下) and bottom up parsers(自下而上).
- Generating parsers automatically—自动生成解析器
There are tools that can generate a parser for you. They are called parser generators(解析生成器). You feed them with the grammar of your language - its vocabulary and syntax rules and they generate a working parser. Creating a parser requires a deep understanding of parsing and its not easy to create an optimized parser by hand, so parser generators can be very useful. Webkit uses two well known parser generators - Flex for creating a lexer and Bison for creating a parser (you might run into them with the names Lex and Yacc). Flex input is a file containing regular expression definitions of the tokens. Bison’s input is the language syntax rules in BNF format. b. HTML Parser—html解析: to parse the HTML markup into a parse tree.
- html语法定义
The vocabulary and syntax of HTML are defined in specificationscreated by the w3c organization. The current version is HTML4 and work on HTML5 is in progress.
- 非自由上下文(context free)语法 As we have seen in the parsing introduction, grammar syntax can be defined formally using formats like BNF. Unfortunately all the conventional parser topics do not apply to HTML (I didn’t bring them up just for fun - they will be used in parsing CSS and JavaScript). HTML cannot easily be defined by a context free grammar that parsers need. There is a formal format for defining HTML -* DTD* (Document Type Definition) - but it is not a context free grammar. This appears strange at first site - HTML is rather close to XML .There are lots of available XML parsers. There is an XML variation of HTML - XHTML - so what’s the big difference? The difference is that HTML approach is more “forgiving”, it lets you omit certain tags which are added implicitly, sometimes omit the start or end of tags etc. On the whole it’s a “soft” syntax, as opposed to XML’s stiff and demanding syntax. Apparently this seemingly small difference makes a world of a difference. On one hand this is the main reason why HTML is so popular - it forgives your mistakes and makes life easy for the web author. On the other hand, it makes it difficult to write a format grammar. So to summarize - HTML cannot be parsed easily, not by conventional parsers since its grammar is not a context free grammar, and not by XML parsers(html不能由常规解析器轻易解析,因为它的语法不是上下文自由的语法,不能由XML解析器(解析)).
- HTML DTD
DTD有一些变体。 严格模式仅符合规范,但其他模式包含对浏览器过去使用的标记的支持。 目的是向后兼容旧内容。 当前严格的DTD在这里: http://www.w3.org/TR/html4/strict.dtd
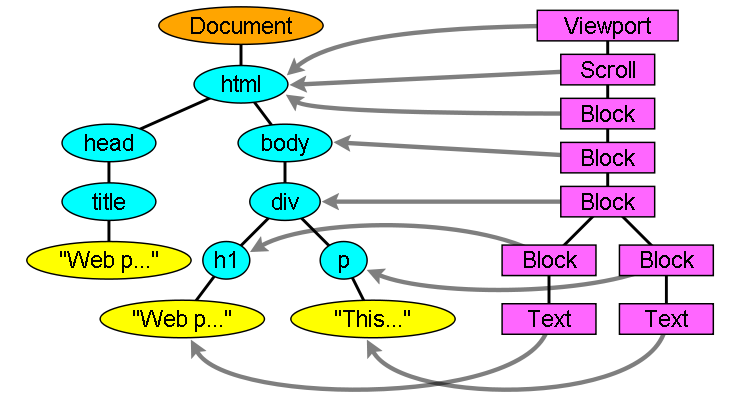
- DOM The output tree(输出树) - the parse tree is a tree of DOM element (元素DOM)and attribute nodes(节点属性). It is the object presentation of the HTML document and the interface of HTML elements to the outside world like JavaScript(是一个代表HTML文档和HTML元素对外部世界如JS提供接口的对象). When I say the tree contains DOM nodes, I mean the tree is constructed of elements that implement one of the DOM interfaces(包含DOM节点的树,便是由实现接口之一的元素们构成的树). Browsers use concrete implementations that have other attributes used by the browser internally.
- The parsing algorithm—解析算法 htnl不能被自上而下的解析规则解析,原因是:
- 语言的原谅本质
- 浏览器含有传统的容错机制去支持广为人知的无效html的事实
- 解析进程可重入。通常来源在解析期间不会更改,但在html中,包含‘document.write’的脚本标记可以添加额外的标记,因此解析过程实际上会修改输入。 无法用正规解析技术,浏览器为html创造了自定义解析器。
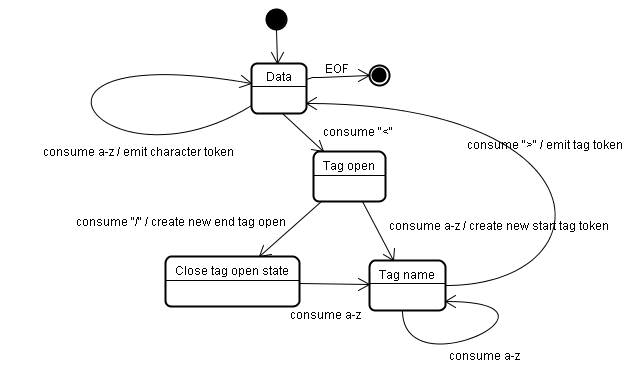
- The tokenization algorithm—标记化算法
The algorithm’s output is an HTML token. 算法输出就是一个HTML符记。 The algorithm is expressed as a state machine(状态机). Each state consumes one or more characters of the input stream and updates the next state according to those characters. The decision is influenced by the current tokenization state and by the tree construction state. This means the same consumed character will yield different results for the correct next state, depending on the current state. The algorithm is too complex to bring fully, so let’s see a simple example that will help us understand the principal.
- 构建树算法
When the parser is created the Document object is created.解析器被构建则文档对象被构建。
- 解析结束后行为
At this stage the browser will mark the document as interactive and start parsing scripts that are in “deferred” mode - those who should be executed after the document is parsed. The document state will be then set to “complete” and a “load” event will be fired. 此阶段,浏览器将文档标记为交互式并解析出于延迟模式的脚本—解析文档之后执行的脚本。而后,文档状态将设置为完成,并触发加载事件
- 浏览器容错 你从未获取到‘Invalid Syntax错误在html页面,浏览器修理无效内容并继续。 c. CSS解析
the CSS specification defines CSS lexical and syntax grammar .CSS的特点决定了CSS lexical 和语法
- webkit CSS 解析器
Webkit uses Flex and Bison parser generators to create parsers automatically from the CSS grammar files.
d. 脚本解析 见js部分 e.脚本及样式处理规则 - 脚本
The model of the web is synchronous(异步的). Authors expect scripts to be parsed and executed immediately when the parser reaches a
<script>tag. The parsing of the document halts until the script was executed. If the script is external then the resource must be first fetched from the network - this is also done synchronously, the parsing halts until the resource is fetched. This was the model for many years and is also specified in HTML 4 and 5 specifications. Authors could mark the script as “defer” and thus it will not halt the document parsing and will execute after it is parsed. HTML5 adds an option to mark the script as asynchronous so it will be parsed and executed by a different thread. - Speculative parsing—推测解析
Both Webkit and Firefox do this optimization. While executing scripts, another thread parses the rest of the document and finds out what other resources need to be loaded from the network and loads them. These way resources can be loaded on parallel connections and the overall speed is better. Note - the speculative parser doesn’t modify the DOM tree and leaves that to the main parser, it only parses references to external resources like external scripts, style sheets and images. Webkit和Firefox都会进行这种优化。 在执行脚本时,另一个线程解析文档的其余部分,并找出需要从网络加载的其他资源并加载它们。 这些方式资源可以并行连接加载,整体速度更好。 注意 - 推测解析器不修改DOM树并将其留给主解析器,它只解析对外部资源的引用,如外部脚本,样式表和图像。
- 样式
Style sheets on the other hand have a different model. Conceptually it seems that since style sheets don’t change the DOM tree, there is no reason to wait for them and stop the document parsing. There is an issue, though, of scripts asking for style information during the document parsing stage. If the style is not loaded and parsed yet, the script will get wrong answers and apparently this caused lots of problems. It seems to be an edge case but is quite common. Firefox blocks all scripts when there is a style sheet that is still being loaded and parsed. Webkit blocks scripts only when they try to access for certain style properties that may be effected by unloaded style sheets.(当存在仍在加载和解析的样式表时,FF会阻止所有脚本;Webkit只在用户视图访问某些可能被卸载的样式表影响的样式属性时阻止脚本)
- Render tree—渲染树 构建 While the DOM tree is being constructed, the browser constructs another tree, the render tree. This tree is of visual elements in the order in which they will be displayed.
Firefox calls the elements in the render tree “frames”. Webkit uses the term renderer or render object.
- 渲染树相对于DOM树 The renderers correspond to the DOM elements, but the relation is not one to one(渲染器与DOM元素对应,但不是一一对应). Non visual DOM elements will not be inserted in the render tree. An example is the “head” element. Also elements whose display attribute was assigned to “none” will not appear in the tree (elements with “hidden” visibility attribute will appear in the tree).
渲染树构建流 In Firefox, the presentation is registered as a listener for DOM updates. The presentation delegates frame creation to the “FrameConstructor” and the constructor resolves style(see style computation) and creates a frame. In Webkit the process of resolving the style and creating a renderer is called “attachment”. Every DOM node has an “attach” method. Attachment is synchronous, node insertion to the DOM tree calls the new node “attach” method. 火狐的呈现被设置为DOM更新的监听,此呈现代理了frameConstructorframe对frame的构建且此构建解决了样式并创造了frame;Webkit中的解决样式和构建render的过程被称为粘贴,每个DOM节点都有一个粘贴的方法。 Processing the html and body tags results in the construction of the render tree root. The root render object corresponds to what the CSS spec calls the containing block - the top most block that contains all other blocks. Its dimensions are the viewport - the browser window display area dimensions. Firefox calls it ViewPortFrame and Webkit calls it RenderView. This is the render object that the document point to. The rest of the tree is constructed as a DOM nodes insertion. (处理html和body标签导致渲染树根的构造。根渲染对象对于CSS规范调用包含块–包含所有其他块最顶层的块。其尺寸即viewport–浏览器窗口显示区域的尺寸。FF调用其ViewPortFrame和Webkit调用其RenderVIew。) See CSS2 on this topic - http://www.w3.org/TR/CSS21/intro.html#processing-model
- 样式计算
Style data is a very large construct, holding the numerous style properties, this can cause memory problems. Finding the matching rules for each element can cause performance issues if it’s not optimized. Traversing the entire rule list for each element to find matches is a heavy task. Selectors can have complex structure that can cause the matching process to start on a seemingly promising path that is proven to be futile and another path has to be tried. For example - this compound selector: div div div div{ … } Means the rules apply to a “<div>” who is the descendant of 3 divs. Suppose you want to check if the rule applies for a given “<div>” element. You choose a certain path up the tree for checking. You may need to traverse the node tree up just to find out there are only two divs and the rule does not apply. You then need to try other paths in the tree. Applying the rules involves quite complex cascade rules that define the hierarchy of the rules. Let’s see how the browsers face these issues:
a. 共享样式数据
Webkit nodes references style objects (RenderStyle) These objects can be shared by nodes in some conditions. The nodes are siblings or cousins and(webkit节点指样式对象(renderstyle),某些情况下该对象可以为节点所共享。节点是兄弟表关系和):
- The elements must be in the same mouse state (e.g., one can’t be in :hover while the other isn’t).元素必须在一些鼠标状态
- Neither element should have an id—也不能共用ID
- The tag names should match—标签名应匹配
- The class attributes should match—class属性应匹配
- The set of mapped attributes must be identical—映射属性应匹配
- The link states must match—链接状态应匹配
- The focus states must match—焦点状态应匹配
- Neither element should be affected by attribute selectors, where affected is defined as having any selector match that uses an attribute selector in any position within the selector at all。元素不应受属性选择器影响。
- There must be no inline style attribute on the elements.元素不能有内联样式。
- There must be no sibling selectors in use at all. WebCore simply throws a global switch when any sibling selector is encountered and disables style sharing for the entire document when they are present. This includes the + selector and selectors like :first-child and :last-child.必须没有使用同级选择器。
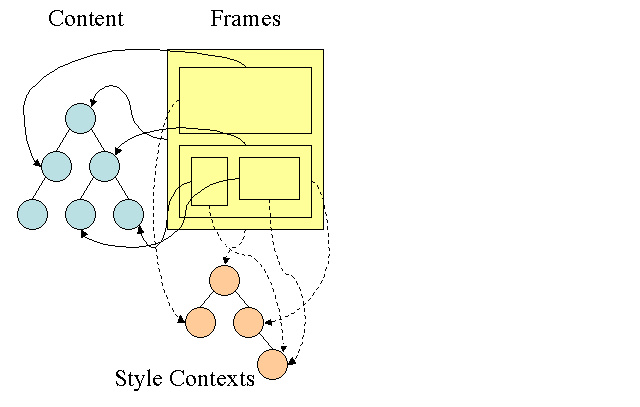
b. FireFox 树规则(有额外的树—规则树和样式文本树,针对更容易的样式计算) Firefox has two extra trees for easier style computation - the rule tree and style context tree. Webkit also has style objects but they are not stored in a tree like the style context tree, only the DOM node points to its relevant style. The style contexts contain end values(样式文本包含终值). The values are computed by applying all the matching rules in the correct order and performing manipulations that transform them from logical to concrete values. For example - if the logical value is percentage of the screen it will be calculated and transformed to absolute units. The rule tree idea is really clever. It enables sharing these values between nodes to avoid computing them again. This also saves space. All the matched rules are stored in a tree. The bottom nodes in a path have higher priority. The tree contains all the paths for rule matches that were found. Storing the rules is done lazily. The tree isn’t calculated at the beginning for every node, but whenever a node style needs to be computed the computed paths are added to the tree. The idea is to see the tree paths as words in a lexicon. Lets say we already computed this rule tree: Suppose we need to match rules for another element in the content tree, and find out the matched rules (in the correct order) are B - E - I.
- Division into structs—分成结构 The style contexts are divided into structs(结构体). Those structs contain style information for a certain category like border or color. All the properties in a struct are either inherited or non inherited(所有属性在结构体中要么继承要么非继承). Inherited properties are properties that unless defined by the element, are inherited from its parent. Non inherited properties (called “reset” properties) use default values if not defined. The tree helps us by caching entire structs (containing the computed end values) in the tree(此树帮我等缓存所有结构体). The idea is that if the bottom node didn’t supply a definition for a struct, a cached struct in an upper node can be used.
- 用树规则计算样式文本 When computing the style context for a certain element, we first compute a path in the rule tree or use an existing one. We then begin to apply the rules in the path to fill the structs in our new style context. We start at the bottom node of the path - the one with the highest precedence (usually the most specific selector) and traverse the tree up until our struct is full. If there is no specification for the struct in that rule node, then we can greatly optimize - we go up the tree until we find a node that specifies it fully and simply point to it - that’s the best optimization - the entire struct is shared. This saves computation of end values and memory. If we find partial definitions we go up the tree until the struct is filled. If we didn’t find any definitions for our struct, then in case the struct is an “inherited” type - we point to the struct of our parent in the context tree, in this case we also succeeded in sharing structs. If its a reset struct then default values will be used. If the most specific node does add values then we need to do some extra calculations for transforming it to actual values. We then cache the result in the tree node so it can be used by children. The resulting rule tree will look like this (the nodes are marked with the node name : the # of rule they point at):
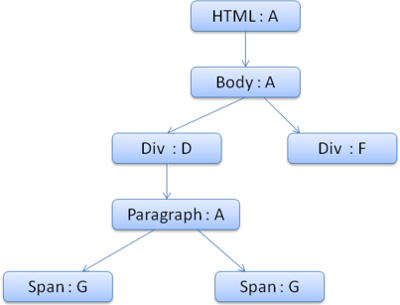
Suppose we parse the HTML and get to the second <div> tag. We need to create a style context for this node and fill its style structs. We will match the rules and discover that the matching rules for the <div> are 1 ,2 and 6. This means there is already an existing path in the tree that our element can use and we just need to add another node to it for rule 6 (node F in the rule tree). We will create a style context and put it in the context tree. The new style context will point to node F in the rule tree. c. Manipulating the rules for an easy match—操作规则方便匹配 There are several sources for style rules:
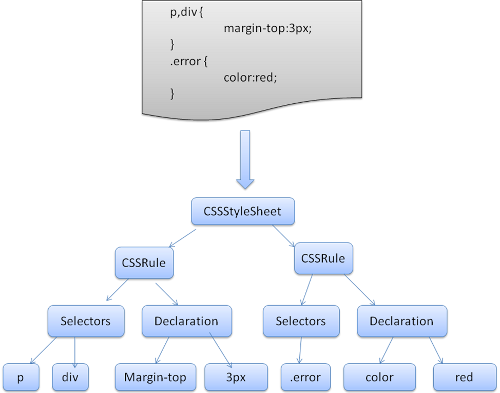
CSS rules, either in external style sheets or in style elements.
p {color:blue}
Inline style attributes like
<p style="color:blue" />
HTML visual attributes (which are mapped to relevant style rules)
<p bgcolor="blue" />
The last two are easily matched to the element since he owns the style attributes and HTML attributes can be mapped using the element as the key.(最后两个很容易地匹配到了元素因其拥有样式属性和html可以利用元素作为key去键映射的属性) d. 正确的瀑布流顺序运用规则
- Style sheet cascade order—CSS规则 A declaration for a style property can appear in several style sheets, and several times inside a style sheet. This means the order of applying the rules is very important. This is called the “cascade” order. According to CSS2 spec, the cascade order is (from low to high)级联顺序(由低到高):
Browser declarations:浏览器声明
User normal declarations:用户正常声明
Author normal declarations:作者正常声明
Author important declarations:作者重要声明
User important declarations:用户重要声明
The browser declarations are least important and the user overrides the author only if the declaration was marked as important. Declarations with the same order will be sorted by specifity and then the order they are specified. The HTML visual attributes are translated to matching CSS declarations . They are treated as author rules with low priority.
- 种类
选择器特性由CSS2规范定义如下: 如果声明是from是一个’style’属性,而不是一个带选择器的规则,则计数1,否则为0(= a) 计数选择器中的ID属性的数量(= b) 计数选择器中其他属性和伪类的数量(= c) 计数选择器中元素名称和伪元素的数量(= d) 连接四个数字a-b-c-d(在具有大基数的数字系统中)给出特异性。 您需要使用的数字基数由您在某个类别中拥有的最高计数来定义。 例如,如果a = 14,您可以使用十六进制基。 在不太可能的情况下,如果a = 17,您将需要一个17位数字基数。 后面的情况可能发生在这样的选择器:html body div div p …(17标签在你的选择器..不是很可能)。
Some examples:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
- 规则排序 After the rules are matched, they are sorted according to the cascade rules. Webkit uses bubble sort for small lists and merge sort for big ones. Webkit implements sorting by overriding the “>” operator for the rules:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2) { int spec1 = r1.selector()->specificity(); int spec2 = r2.selector()->specificity(); return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2; }
- Gradual process—渐进过程 Webkit使用标记是否已加载所有顶级样式表(包括@imports)的标志。 如果在附加时样式未完全加载 - 使用占位符并在文档中标记,并且一旦样式表被加载,它们将被重新计算。
- Layout
- Dirty bit system脏位系统 In order not to do a full layout for every small change, browser use a “dirty bit” system. A renderer that is changed or added marks itself and its children as “dirty” - needing layout.
There are two flags - “dirty” and “children are dirty”. Children are dirty means that although the renderer itself may be ok, it has at least one child that needs a layout.
- Global and incremental layout—全局和增量布局
- Asynchronous and Synchronous layout—异同布渲染
- Optimizations—选择
- The layout process 布局过程 The layout usually has the following pattern:
Parent renderer determines its own width. Parent goes over children and: Place the child renderer (sets its x and y). Calls child layout if needed(they are dirty or we are in a global layout or some other reason) - this calculates the child’s height. Parent uses children accumulative heights and the heights of the margins and paddings to set it own height - this will be used by the parent renderer’s parent. Sets its dirty bit to false. Firefox uses a “state” object(nsHTMLReflowState) as a parameter to layout (termed “reflow”). Among others the state includes the parents width. The output of Firefox layout is a “metrics” object(nsHTMLReflowMetrics). It will contain the renderer computed height.
- Width calculation 宽度计算
- Line breaking 换行
- Painting—喷涂
全局和增量 Like layout, painting can also be global - the entire tree is painted - or incremental. In incremental painting, some of the renderers change in a way that does not affect the entire tree. The changed renderer invalidates it’s rectangle on the screen. This causes the OS to see it as a “dirty region” and generate a “paint” event. The OS does it cleverly and coalesces several regions into one. In Chrome it is more complicated because the renderer is in a different process then the main process. Chrome simulates the OS behavior to some extent. The presentation listens to these events and delegates the message to the render root. The tree is traversed until the relevant renderer is reached. It will repaint itself (and usually its children).
- 喷涂规则 The stacking order of a block renderer is: 1.background color 2.background image 3.border 4.children 5.outline
- FF 布局列表 Firefox goes over the render tree and builds a display list for the painted rectangular. It contains the renderers relevant for the rectangular, in the right painting order (backgrounds of the renderers, then borders etc). That way the tree needs to be traversed only once for a repaint instead of several times - painting all backgrounds, then all images , then all borders etc. Firefox optimizes the process by not adding elements that will be hidden, like elements completely beneath other opaque elements.
- Webkit rectangle storage矩形存储 Before repainting, webkit saves the old rectangle as a bitmap. It then paints only the delta between the new and old rectangles.
- 动态改变 The browsers try to do the minimal possible actions in response to a change. So changes to an elements color will cause only repaint of the element. Changes to the element position will cause layout and repaint of the element, its children and possibly siblings. Adding a DOM node will cause layout and repaint of the node. Major changes, like increasing font size of the “html” element, will cause invalidation of caches, relyout and repaint of the entire tree.
- 渲染引擎线程
- 事件循环
- CSS2 视觉模型
- canvas
- CSS Box model
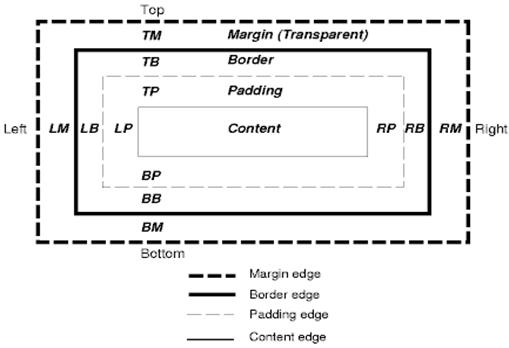
- Positioning scheme—定位方案
- Box types—盒类型 Block box: forms a block - have their own rectangle on the browser window. Inline box: does not have its own block, but is inside a containing block. Blocks are formatted vertically one after the other. Inlines are formatted horizontally.
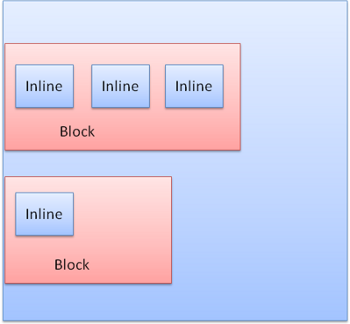
- 定位 a. relative b. floats c. absolute and fixed
- Layered representation—分层表现
- 资源
Leave a Comment